

In InvoiceR erfasste Rechnungs-Belege werden zukünftig automatisch erkannt: Dies bedeutet, dass Informationen wie die Lieferanten-Adresse, Zahlungs-Verbindung, Beträge und weiteres dank künstlicher Intelligenz aus dem Dokument extrahiert werden und InvoiceR für die weitere Bearbeitung zur Verfügung stehen.
Diese hohe Kunst der Datenerkennung wird durch die nahtlose Integration der Parashift-Services ermöglicht. Für den InvoiceR-Nutzer unsichtbar, werden Parashift die gescannten Dokumente zur Verfügung gestellt und in einem ersten Schritt durch künstliche Intelligenz analysiert.
In seltenen Fällen ist sich die automatische Intelligenz nicht sicher, dann bearbeiten die Mitarbeiter:innen der Parashift den Beleg manuell. Durch dieses optionale menschliche Eingreifen ist eine sehr hohe Automatisierung in der Nutzung von InvoiceR erreichbar.
Live-Webinar von Parashift und enio
Am 6. Mai 2021 haben Sie die Gelegenheit, die Integration der Parashift-Services in InvoiceR an einem Webinar für Schweizer KMU live mitzuverfolgen. Darin besprechen Sebastian Wilke und Thomas Kohler, wie automatisierte Rechnungsextraktion und nachgelagerte digitale Verbuchungsprozesse Ihrem Unternehmen zu erhöhtem Durchsatz verhelfen kann und welche neue Opportunitäten sich daraus ergeben.
Wie kommen meine Rechnung in den Workflow?
Es gibt verschiedene Möglichkeiten eine Rechnung im Kreditorenworkflow zu erfassen. Grundvoraussetzung ist, dass die Rechnung als ein elektronisches Dokument vorliegt. Haben Sie die Rechnung physisch auf einem Blatt Papier, muss dieses Papier zuerst gescannt werden. Nach dem Scan haben Sie dann ein elektronisches Bild oder ein Dokument (z.B. PDF).
Haben Sie die Rechnung per Email oder einer Schnittstelle bereits elektronisch erhalten, entfällt der Vorgang des Scannens.
Nur scannen reicht nicht - OCR wird verlangt
Nach dem Scannen haben Sie das Dokument elektronisch und können dieses speichern. Beim Speichern in einem elektronischem Archiv darf das physische Original-Dokument nun sogar vernichtet werden.
Damit nun weitere Automatisierungsschritte mit dem Dokument gemacht werden können, muss herausgefunden werden, was in diesem Dokument drin steht. Das ist keine einfache Aufgabe, denn nach dem Scan handelt es sich beim Dokument eigentlich nur um ein Bild mit verschieden farbigen Punkten. Hier kommt nun die automatische Text-Erkennung (OCR: Optical Character Recognition) ins Spiel.
Ein OCR-System analysiert das gescannte Bild und erkennt den Text darin. Als Ergebnis dieser Analyse werden Text-Schnipsel und die dazugehörenden Koordinaten im Dokument geliefert. Solche Systeme gibt es bereits seit vielen Jahren und liefern heutzutage bei einer guten Scan-Qualität hervorragende Ergebnisse.
OCR genügt auch nicht
Nach der Text-Erkennung ist nun bekannt was für Text-Schnipsel im Dokument vorhanden sind und wo diese zu finden sind. Diese Informationen sind für ein Dokumentenarchiv sehr nützlich. Dadurch kann sehr schnell ein Dokument gefunden werden, welches einen bestimmten Text beinhaltet.
Um die Verarbeitung der Eingangsrechnungen möglichst effizient zu gestalten, reicht dies noch nicht. Die einzelnen Text-Schnipsel aus dem OCR-Prozess müssen ausgewertet und hinsichtlich des Informations-Typs untersucht werden. Enthält ein Text-Schnipsel z.B. ein Datum, kann es sich dabei um das Liefer-, Rechnungs- oder Zahlungsdatum einer Rechnung handeln. Eine erkannte Zahl kann der Rechnungsbetrag oder die Kundennummer sein.
Für Menschen ist diese Kategorisierung meistens trivial – doch ein Computer-System muss auch heutzutage noch tief in die Trickkiste greifen um solche Unterscheidungen durchführen zu können.
Dokumentdatenextraktion und -klassifikation-Systeme
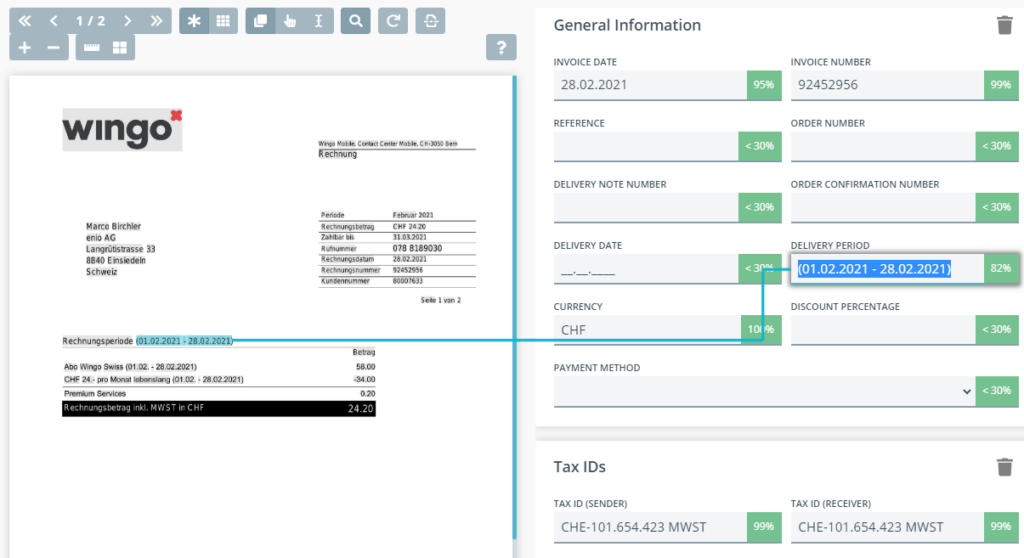
Integration der Dokumentdaten-Extraktion in InvoiceR
Im Zusammenhang mit der Parashift-Partnerschaft wurde InvoiceR nun um eine Datenextraktions-Schnittstelle erweitert, welche es InvoiceR erlaubt, Dritt-Systeme für diese anspruchsvolle Aufgabe direkt einzubinden. Dadurch wird die Extraktion und Klassifikation der Rechnungs-Belege zu einem integrierten Bestandteil von InvoiceR und ist nicht mehr ein vorgelagerter Prozess.
